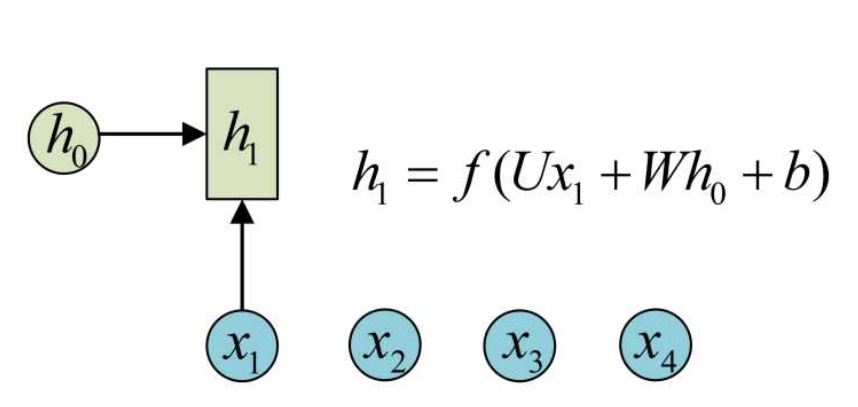
新的算法理论不断涌现的同时,各种深度学习框架也不断出现在人们视野,比如Torch,Caffe等等。TensorFlow是Google开发的第二代机器学习系统,于2015年底开源,成为了新一代流行的机器学习的算法框架。这一章节我们将tensorFlow怎么实现循环神经网络(RNN)。
单步的RNN:RNNCell
假设我们有一个初始状态h0,还有输入x1,调用call(x1, h0)后就可以得到(output1, h1):

再调用一次call(x2, h1)就可以得到(output2, h2):

也就是说,每调用一次RNNCell的call方法,就相当于在时间上“推进了一步”,这就是RNNCell的基本功能。
RNNCell只是一个抽象类,我们用的时候都是用的它的两个子类BasicRNNCell和BasicLSTMCell。这两个类的重要属性。
1.state_size
2.output_size
前者是隐层的大小,后者是输出的大小。比如我们通常是将一个batch送入模型计算,设输入数据的形状为(batch_size, input_size),那么计算时得到的隐层状态就是(batch_size, state_size),输出就是(batch_size, output_size)。
对于BasicLSTMCell,情况有些许不同,因为LSTM可以看做有两个隐状态h和c,对应的隐层就是一个Tuple,每个都是(batch_size, state_size)的形状:
对于单个的RNNCell,我们使用它的call函数进行运算时,只是在序列时间上前进了一步。比如使用x1、h0得到h1,通过x2、h1得到h2等。这样的h话,如果我们的序列长度为10,就要调用10次call函数,比较麻烦。对此,TensorFlow提供了一个tf.nn.dynamic_rnn函数,使用该函数就相当于调用了n次call函数。即通过{h0,x1, x2, …., xn}直接得{h1,h2…,hn}。
具体来说,设我们输入数据的格式为(batch_size, time_steps, input_size),其中time_steps表示序列本身的长度,如在Char RNN中,长度为10的句子对应的time_steps就等于10。最后的input_size就表示输入数据单个序列单个时间维度上固有的长度。另外我们已经定义好了一个RNNCell,调用该RNNCell的call函数time_steps次,对应的代码就是:
此时,得到的outputs就是time_steps步里所有的输出。它的形状为(batch_size, time_steps, cell.output_size)。state是最后一步的隐状态,它的形状为(batch_size, cell.state_size)。
经典RNN结构图:

import tensorflow as tf
import numpy as np
from tensorflow.contrib import rnn
from tensorflow.examples.tutorials.mnist import input_data
from PIL import Image
import numpy as np
# import scipy
import matplotlib.pyplot as plt
import numpy as np
import pylab
config = tf.ConfigProto()
sess = tf.Session(config=config)
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
print mnist.train.images.shape
# 学习率
lr = 1e-3
# 在训练和测试的时候,我们想用不同的 batch_size.所以采用占位符的方式
batch_size = tf.placeholder(tf.int32, [])
# 每个时刻的输入特征是28维的,就是每个时刻输入一行,一行有 28 个像素
input_size = 28
# 时序持续长度为28,即每做一次预测,需要先输入28行
timestep_size = 28
# 每个隐含层的节点数
hidden_size = 64
# LSTM layer 的层数
layer_num = 2
# 最后输出分类类别数量,如果是回归预测的话应该是 1
class_num = 10
_X = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, class_num])
keep_prob = tf.placeholder(tf.float32)
# 把784个点的字符信息还原成 28 * 28 的图片
# 下面几个步骤是实现 RNN / LSTM 的关键
X = tf.reshape(_X, [-1, 28, 28])
def unit_lstm():
# 定义一层 LSTM_cell,只需要说明 hidden_size, 它会自动匹配输入的 X 的维度
lstm_cell = rnn.BasicLSTMCell(num_units=hidden_size, forget_bias=1.0, state_is_tuple=True)
#添加 dropout layer, 一般只设置 output_keep_prob
lstm_cell = rnn.DropoutWrapper(cell=lstm_cell, input_keep_prob=1.0, output_keep_prob=keep_prob)
return lstm_cell
#调用 MultiRNNCell 来实现多层 LSTM
mlstm_cell = rnn.MultiRNNCell([unit_lstm() for i in range(3)], state_is_tuple=True)
#用全零来初始化state
init_state = mlstm_cell.zero_state(batch_size, dtype=tf.float32)
outputs, state = tf.nn.dynamic_rnn(mlstm_cell, inputs=X, initial_state=init_state, time_major=False)
h_state = outputs[:, -1, :] # 或者 h_state = state[-1][1]
# 把784个点的字符信息还原成 28 * 28 的图片
# 下面几个步骤是实现 RNN / LSTM 的关键
X = tf.reshape(_X, [-1, 28, 28])
def unit_lstm():
# 定义一层 LSTM_cell,只需要说明 hidden_size, 它会自动匹配输入的 X 的维度
lstm_cell = rnn.BasicLSTMCell(num_units=hidden_size, forget_bias=1.0, state_is_tuple=True)
#添加 dropout layer, 一般只设置 output_keep_prob
lstm_cell = rnn.DropoutWrapper(cell=lstm_cell, input_keep_prob=1.0, output_keep_prob=keep_prob)
return lstm_cell
#调用 MultiRNNCell 来实现多层 LSTM
mlstm_cell = rnn.MultiRNNCell([unit_lstm() for i in range(3)], state_is_tuple=True)
#用全零来初始化state
init_state = mlstm_cell.zero_state(batch_size, dtype=tf.float32)
outputs, state = tf.nn.dynamic_rnn(mlstm_cell, inputs=X, initial_state=init_state, time_major=False)
h_state = outputs[:, -1, :] # 或者 h_state = state[-1][1]
W = tf.Variable(tf.truncated_normal([hidden_size, class_num], stddev=0.1), dtype=tf.float32)
bias = tf.Variable(tf.constant(0.1,shape=[class_num]), dtype=tf.float32)
y_pre = tf.nn.softmax(tf.matmul(h_state, W) + bias)
# 损失和评估函数
cross_entropy = -tf.reduce_mean(y * tf.log(y_pre))
train_op = tf.train.AdamOptimizer(lr).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess.run(tf.global_variables_initializer())
for i in range(1000):
_batch_size = 128
batch = mnist.train.next_batch(_batch_size)
if (i+1)%200 == 0:
train_accuracy = sess.run(accuracy, feed_dict={
_X:batch[0], y: batch[1], keep_prob: 1.0, batch_size: _batch_size})
# 已经迭代完成的 epoch 数: mnist.train.epochs_completed
print "Iter%d, step %d, training accuracy %g" % ( mnist.train.epochs_completed, (i+1), train_accuracy)
sess.run(train_op, feed_dict={_X: batch[0], y: batch[1], keep_prob: 0.5, batch_size: _batch_size})
images=mnist.test.images
labels=mnist.test.labels
print "test accuracy %g"% sess.run(accuracy, feed_dict={
_X: images, y: labels, keep_prob: 1.0, batch_size:mnist.test.images.shape[0]})
 扫一扫获取最新精彩内容与学习资料
扫一扫获取最新精彩内容与学习资料
人工智能技术网 倡导尊重与保护知识产权。如发现本站文章存在版权等问题,烦请30天内提供版权疑问、身份证明、版权证明、联系方式等发邮件至1851688011@qq.com我们将及时沟通与处理。!:首页 > 大数据 » 循环神经网络RNN的实现