
热闹纷繁的 OLAP 赛道,又迎来一个开源新玩家。
这几年 OLAP 赛道持续火热,国内外不少开源项目和商业公司活跃其中。在一众玩家中,ClickHouse 凭借彪悍的性能表现、活跃的开源社区和相当快的迭代速度,市场普及率一路狂飙。
围绕 ClickHouse,最近有两则新闻颇引人关注:一个是阿里云官宣与 ClickHouse 商业公司合作,成为 ClickHouse 在中国独家的云服务提供商;另一个则是字节跳动 ByteHouse 与亚马逊云科技合作推出新一代云数仓服务。两种不同的组合,背后其实是国内外市场对 ClickHouse 云原生化产品和应用的浓厚兴趣。
作为国内极具代表性的 ClickHouse 大规模采用者,字节跳动在历经数年的 ClickHouse 云原生化改造和应用中沉淀了许多宝贵的实践经验和思考。2021 年 8 月,字节跳动将经过多年定制化改造的 ClickHouse,沉淀为 ByteHouse 对外提供服务。自那时起,就有人猜测:ByteHouse 会不会开源?
其实字节跳动为开源准备已久。今年,字节跳动将 ByteHouse 内核向社区开源为 ByConity,并于近日正式官宣发布 0.1.0 版本。
ByConity 定位为开源的云原生数据仓库,采用 Apache 2.0 许可协议,基于 ClickHouse 内核,但采用了存储计算分离的全新架构,支持多个关键功能特性,如存储计算分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的 OLAP 引擎优化,如列存储、向量化执行、MPP 执行、查询优化等,ByConity 可以提供优异的读写性能。ByConity 适合用于 Online Analytical Processing(OLAP)场景和轻载数仓场景,包括但不限于交互式分析、实时日志监控、流数据处理和分析等。
借此机会,InfoQ 独家采访了 ByConity 背后的技术团队,深入了解 ByConity 开源准备过程、架构亮点、ByConity 与 ClickHouse 的差异,以及 ByConity 后续规划等问题。这也是 ByConity 开源后团队首次接受采访。
一、开源准备

为了和早些推出的商业品牌作区分、避免用户混淆,团队为开源版本取了新名字 ByConity。新名字由三个英文单词组合再生而来:
By 来自 Byte,代表存储数据的基本单位,也比喻海量数据;
Con 来自 Convert,代表改变和革新;
Conity 也来自 Community,代表一群人,也就是开源开发者社区。
从采用 ClickHouse 遇到痛点进而自研改造,到推出商业化服务 ByteHouse,再到现在推出开源项目 ByConity,陈星认为这是一个自然而然的过程,ByteHouse 和 ByConity 背后实际也是同一个技术团队在支持。在他看来,行业内有很多公司和团队存在使用 ClickHouse 的痛点,对于解决这些问题并进一步拓宽其使用场景感兴趣。开源能够带来更多技术层面的合作,也能帮助 ByConity 更快地扩展到更广泛的不同行业中去,这是推动团队将 ByConity 开源出来的重要动机之一。
在决定开源之前,团队也考虑过是否能将自研修改合并回 ClickHouse 社区,并围绕向社区完整贡献和联合开发,与 ClickHouse 核心研发团队、ClickHouse 创业公司负责人做了几次闭门沟通,但得到的反馈是架构差异过大、合并难度和代价大、无法联合开发。最终按照 ClickHouse 社区给到的建议,团队决定独立开源,并跟 ClickHouse 社区进行了消息同步。
2022 年 5 月,团队启动 ByConity 开源相关研发和准备工作。到正式开源这期间,技术层面关键迭代主要有以下几点:
1.升级 ByConity Codebase,和社区 ClickHouse 21.8 版本代码做同步,因为最初字节跳动引入 ClickHouse 的时候用的还是早期版本,但 ClickHouse 社区在版本 19 到 22 之间做了比较大的重构,导致整个执行 model 发生了一些变化,这部分需要做不少代码重写工作,将整个代码基线提升到社区新的 LTS 版本;
2.移除公司内部依赖组件,寻找对应的开源替代方案做兼容和适配,比如 FoudationDB 适配、ClickHouse-Keeper 适配等;
3.基于 Processor Model 重构 MPP 实现,提升性能与稳定性:主要解决了 ClickHouse 对于复杂 Query 的执行支持不好,功能也比较局限(Join 只支持 broadcast join)等问题;适配 ClickHouse 新版本基于 Processor Push Mode 的执行模式;
4.优化器迭代,重点迭代了优化规则(RBO),CBO 方面重点增强统计信息自动收集等:比如当用户表有改动时,后台任务会检查统计信息表的修改行数,当达到一定阈值时触发自动收集;
5.云原生架构设计下,增强数仓场景的查询性能,数据能够自动预读,避免被动 cache 在实时场景下缓存命中率低的问题:支持 HDFS/S3 等分布式文件系统或者对象存储系统,并针对不同的分布式存储系统做了读写性能优化,存储系统中也实现了基于本地磁盘的二级缓存系统,可以采用高性能本地盘来进一步加速存储读写性能。
前两点主要是为对外开源做准备,后三点则是在原来内部版本基础上进一步优化升级。除了技术层面的准备,还涉及公司开源流程、代码合规、工程质量、配套部署工具开发等一系列相关准备。
据陈星介绍,ByConity 开源非常彻底,引擎核心能力都开源了,只有因公司合规要求受限的部分做了一些裁剪。本质上 ByteHouse 云数仓的内核就是 ByConity,引擎能力基本一样。后续 ByteHouse 研发新功能,也会直接在 ByConity 基础上用开源的模式做,这对于团队的研发模式来说是一个非常大的改变。
作为正式官宣开源前准备工作的关键一环,今年 1 月,团队发布了 ByConity beta(v0.1.0-beta)版本,并在社区小范围征集用户试用。过去四个月陆陆续续已经有不少团队试用 ByConity 并在 GitHub 上提 issue 反馈,其中有一些团队已经在验证生产场景中的数据和工作负载。翟鹿渊表示,希望通过这样的小范围试用,确认 ByConity 能真正帮助大家解决问题、带来好处,再正式开源,让更广泛的用户知道该如何使用 ByConity、能真正把 ByConity 用起来。比起一开始就官宣开源,这可能是一种相对谨慎但更务实的做法。
二、社区反响
Beta 版本推出后,ByConity 团队从社区得到了不少反馈。好的一面是,有不少团队和开发者对 ByConity 表现出浓厚兴趣,其中不乏知名科技公司和团队,比如传音控股、电子云、华为、美团、天翼云、唯品会等,都在积极测试和验证。据翟鹿渊介绍,目前国内采用了 ClickHouse 的公司中,ByConity 大致覆盖了头部的三分之一,都是使用规模相对比较大的。其中华为终端云团队已经参与到了 ByConity 部分研发工作中,比如这次发布的 0.1.0 版本中有一个对象存储集成功能的预览版,就是华为终端云团队参与共同开发的。
当然难免也会出现一些挑战。在知乎 ByConity 相关问题下面,有网友反馈代码风格对开发者不是很友好,一个方法里几百上千行代码,批评 ByConity 肯定是延续了 ClickHouse 开源代码的问题。对此,陈星表示虚心接受批评,ByConity 本身就是基于 ClickHouse 内核开发,因此 CH 的代码风格问题,ByConity 难以避免,再加上早期内部研发更多追求快速上线使用,对于代码风格可能没有特别高要求和统一规范。目前 ByConity 团队已经在规划和推进代码重构工作、希望做出好的示范,也希望后续社区能够一起推进这项工作。
类似的问题,翟鹿渊也被问到过,比如有开发者认为 ByConity 的代码和 ClickHouse 重合度比较高。潜在的质疑或挑战点在于,ByConity 不是一个完全自主研发的项目。对此团队的态度很坦荡,ByConity 的起点是 ClickHouse,这是事实,作为 ClickHouse 的下游项目,ByConity 会在向上兼容性方面做基础保证,并在开源许可的 header 文件中对受益于哪些开源项目给到完整的说明。
ByConity 不会为了体现差异而做代码调整(比如重命名一些函数、在命名空间上做些修饰等)。ByConity 希望能够继承 ClickHouse 的长处和优势,比如性能上的优势、工程设计上的亮点等,ByConity 都会继续保留;同时针对实际业务场景中需要解决的问题,ByConity 会在新架构上做延展,以求在更广泛的场景上发挥出更大作用,让更多公司或团队受益。
三、架构亮点与差异
从 2017 年引入 ClickHouse 至今,ByConity 团队基于 ClickHouse 内核做了深度改造和大量升级优化,不管是技术难度还是技术投入程度都非常大。具体的优化思路在早前的采访和白皮书做过详细说明,近期 ByConity 社区也会联合 InfoQ 陆续发布一系列 ByConity 技术解读文章。
目前 ByConity 整体架构如下图所示,分为 3 层:服务接入层、计算层和存储层,其中服务接入层响应用户查询,计算层负责计算数据,存储层存放用户数据。详细介绍可查阅 ByConity 的整体架构说明文档。
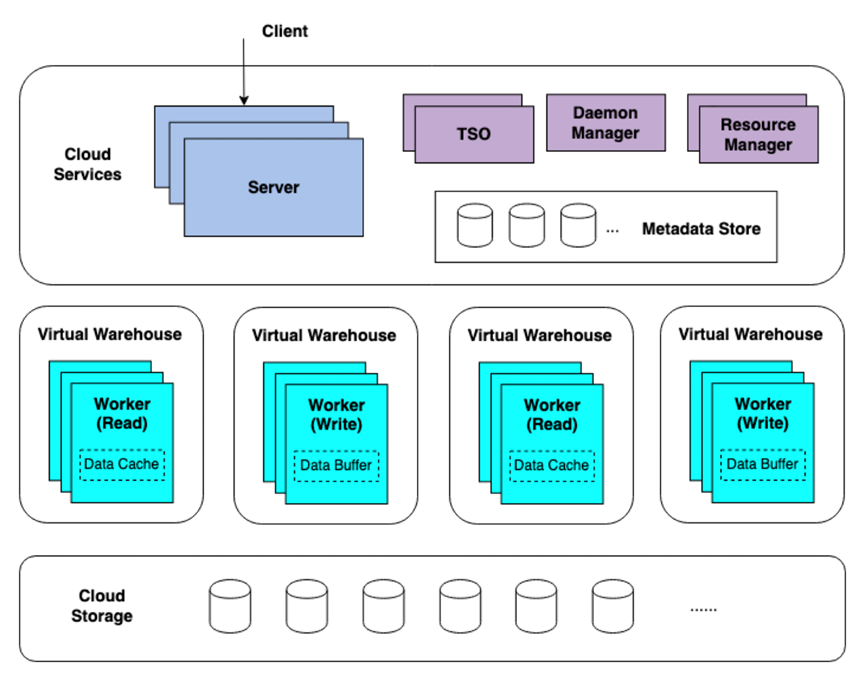
ByConity 最新架构图
基于从外部收到的反馈,翟鹿渊将 ByConity 相比传统 MPP 架构的亮点概括为以下三点:
首先是存储计算分离的改造。传统 MPP 很难对计算资源做隔离,据翟鹿渊介绍,现在业界大多数使用 ClickHouse 方案的公司和团队,采用的隔离方式基本是靠物理集群隔离,运维管理成本极高。存算分离之外,ByConity 依托于虚拟化容器调度能力,既能实现业务和业务之间的隔离,又能非常灵活地调配硬件资源,这其实是很多公司想解决,但可能只解了一半或者暂时还没有好解决方案的严重问题。
其次是自研的面向 ClickHouse runtime 执行层、与之完全匹配的查询优化器。基于四个大方向(基于规则、基于 cost、基于数据依赖、基于反馈)提供极致优化能力,能极大提高查询性能,特别是在复杂查询场景下能带来数倍至数百倍的性能提升。虽然业界成熟的数仓引擎都会配备查询优化器,但据了解,从 ClickHouse 技术方案衍生出来的查询优化器,目前在业界应该没有第二个方案。
然后是对元数据存储和管理的优化。使用 ClickHouse 比较多的团队可能都会遇到一个问题,随着集群管理的元数据越来越多,ZooKeeper/Keeper 会面临很大的 coordinate 压力,可能出现元数据不一致的问题,轻则查询报错,重则整个集群宕机。这类问题在 ByConity 从系统层面得到了解决。ByConity 基于高性能的分布式 key-value store(FoundationDB)做元数据管理,并在 catalog api 上层实现了完备事务语义(ACID)支持,提供了高效可靠的元数据服务,能够将元数据吞吐拉升到百万级别。
除了架构上的差异化亮点,ByConity 和 ClickHouse 在使用过程中又有哪些异同?社区也有不少开发者对此有疑问。前不久 ByConity 社区组织了一场直播,从使用角度对两者差异做了介绍,主要从以下几个关键维度展开:
在资源隔离与扩缩容设计上的架构与组件差异
在库表创建、数据导入与查询上的差异
在事务支持与特殊表引擎上的差异
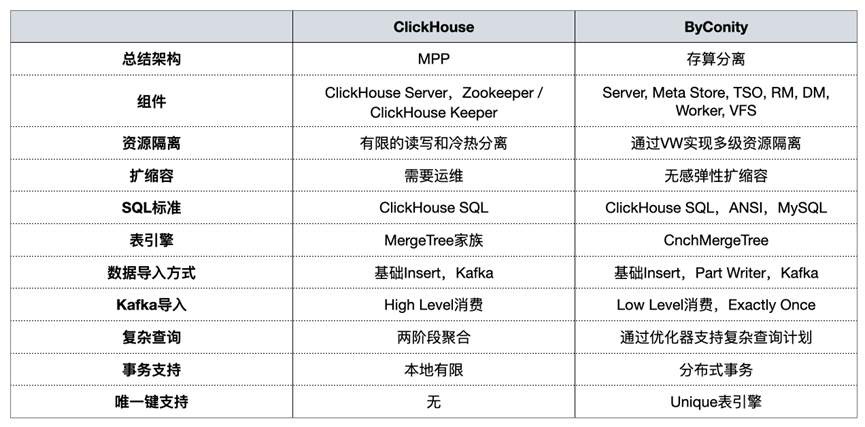
ByConity 与 ClickHouse 的差异总结(来源:ByConity 社区)
感兴趣的读者可以在bilibili搜索ByConity官方账号查看直播回放视频进一步了解。
四、后续规划
随着 ByConity 正式官宣开源,后续项目会遵循开源社区的模式来运营和治理,社区治理原则相关的文档目前已经同步到项目 GitHub 上,并面向整个社区开放讨论。
对于 ByConity 接下来的技术发展路线,团队基于自身现状初步做了一些规划,今年下半年侧重点会放在权限控制、数据安全和组件高可用等方向。还有一些社区关注度比较高的问题,比如对数据湖分析的支持,包括对接 Hudi、Iceberg 等功能,也在 Roadmap 规划之中。
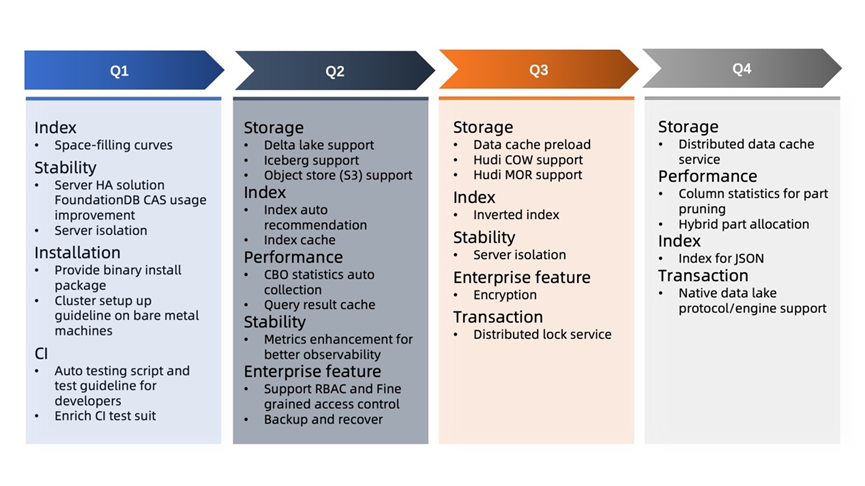
ByConity 2023 年技术路线 Roadmap
陈星表示,未来 ByConity 希望从一个只面向即时型分析的轻量级数仓,向一个能够处理更多复杂工作负载、更成熟的数仓去演化。当然,这其中挑战非常大,也不是短时间内能够做好的,需要与社区共同努力。
对于一个新的开源项目,社区往往会非常关注项目的长期投入和发展问题。翟鹿渊表示,字节去年成立开源委员会,就是字节更加重视开源的一个信号,而开源委员会有一条原则是做精品项目,从公司层面会聚焦少数重点项目做长期的战略投入,ByConity 是其中之一。另外,如前所述,ByConity 和 ByteHouse 研发团队基本是完全重合的,只是每个人的工作有一部分在做商业版、一部分在解决开源社区相关反馈,开源和商业版融合度非常高。未来 ByConity 会朝着一个更加开放的引擎开发模式去发展,今年年中会将内外部代码层面完全拉齐,后续对 ByteHouse 的改动会基于 ByConity 源代码用开源的方式来开发,即先在上游开发,开发完成后在再往回拉。这个开发模式调整可以说是大动干戈,但也从侧面印证了字节长期投入 ByConity 的决心。
未来除了 ByConity 社区自身的代码贡献,字节内部业务场景、ByteHouse 的客户场景带来的迭代和改进也会反哺给 ByConity,帮助 ByConity 持续迭代优化。比如,字节内部使用规模还在逐步增大,可能会打破以往设计方案的一些假设条件,导致调度策略或者资源分配策略要适应内部业务做优化和调整,这些优化都会输出到 ByConity。商业化产品同理,商业版用户在使用中遇到的问题或反馈的修改,也会同步到 ByConity。
五、写在最后
对于一个开源项目,引入更多参与者、让社区往多元化方向发展往往是重要目标之一,ByConity 也不例外。从发布 Beta 版开始,ByConity 团队就公布了社区路线图,并积极与社区成员共同探讨和解决大家在试用过程中遇到的问题,团队有耐心、也有信心,更是非常期待未来能够与更多开发者和合作伙伴一起共建共享,激发更多创造力。
对于社区多元化可能会给项目创始团队带来的新问题,比如项目无法按照最初规划的技术发展路线演进等,陈星和翟鹿渊都表示,希望这个幸福的烦恼早些到来。
网页搜索「GitHub - ByConity」查看官方地址;
ByConity官方微信公众号回复「用户手册」,获取ByConity完整背景和技术架构。

采访嘉宾介绍:
陈星,火山引擎分析型数据库负责人,具体包括 ClickHouse、Doris、下一代云原生数据库,支持内部多种业务场景背后分析引擎。加入字节跳动数据平台之前,在 IBM 从事 DB2 内核研发工作,对数据库技术有一些了解。
翟鹿渊,火山引擎 ByteHouse 产品经理,主导 ByteHouse 海外商业化和引擎 ByConity 开源。之前在 Kyligence 做 Apache Kylin 商业产品。
人工智能技术网 倡导尊重与保护知识产权。如发现本站文章存在版权等问题,烦请30天内提供版权疑问、身份证明、版权证明、联系方式等发邮件至1851688011@qq.com我们将及时沟通与处理。!:首页 > 数字经济 » 字节跳动开源ByConity:基于ClickHouse的存算分离架构云原生数仓